
An Update to our DECICE Framework Architecture
Some time has passed since the first presentation of the DECICE framework architecture and with continuous progression of the project, the requirements for the architecture have started to take shape. Today we are presenting the newly emerged technical descriptions of the system characteristics and its corresponding changes, which will lay the foundation for the upcoming development process.
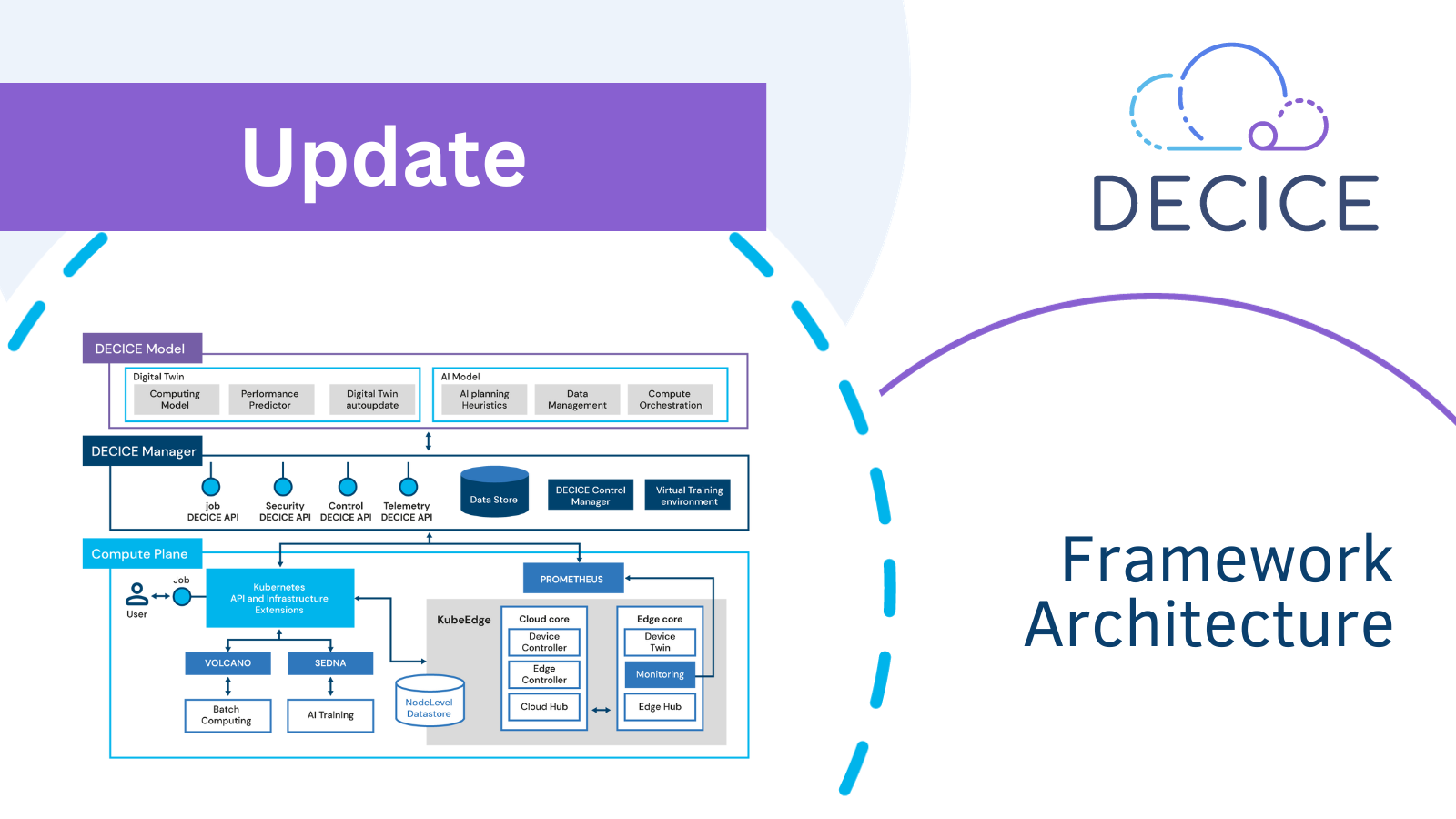
Just like in previous versions of the DECICE framework (cf. picture below), the architecture is still divided into three main components: the framework itself, which is responsible for preparing and arranging computational jobs, workloads and services, the DECICE model, which takes care of the Digital Twin (DT) along with the schedulers and the compute plane, which is responsible for the actual execution of work and running services.
But the closer the new deliverables approached us it became apparent that a new, more sophisticated image of the architecture was necessary in order to get a better understanding of how the internal software components are aligned and work together. Today we are presenting a new technical description of the system characteristics of the DECICE framework (cf. new architecture) and provide a detailed overview of the high-level architecture. If you want to read about the first iteration of the DECICE architecture, you can find the news article here.
Colour Legend for New Architecture of DECICE Framework
To get a better understanding of the inner workings and procedures of the components we provide a colour legend with details about the information flow within the architecture.
|
Light Blue boxes |
Components that are developed through the DECICE project |
|
Purple boxes |
Components that already exist in some form and need to be deployed and configured through the DECICE project |
|
Light Blue arrows |
Part of system monitoring |
|
Purple arrows |
Part of the scheduling and other automatic control loops |
|
Dark Blue arrows |
Part of system administration invoked automatically or by admins |
|
Black arrows |
Users and admins interacting with the system |
DECICE Framework
The DECICE framework favours a component-based composition for its architectural approach, which enables switching between different implementations of the same component. Therefore, the platform can be specified and implemented as a set of interfaces that reflect the organizational structure of the project. Additionally, components interacting with external interfaces can be swapped out or updated if the external interfaces change without affecting the internal components.
Starting with the heart of the framework, the DECICE Control Manager, which is responsible for dealing with the majority of the business logic and is central to almost all control flows in the framework. In order to store settings, configuration and data relevant for the DECICE framework, the control manager has its own database, the DECICE Config-Store.
The DECICE API exposes two components for interactions with the underlying platform, the end user API (job and telemetry) and the admin API (control and security). The end user API provides interfaces to submit jobs, deployments and workloads. These submissions are processed by the control manager and then stored to be considered during future scheduling decisions. Furthermore, it can also be used to send queries to the metrics storage, while considering user permission to determine what queries are allowed.
The Platform Specific Glue Code serve as an integration of the control manager with the underlying platform. Here the compute plane is managed by Kubernetes but by swapping them out, they could also support another orchestration platform such as Hashicorp Nomad or Apache Mesos. The wrapper glue code serves as an abstraction for controlling the KubeAPI without having to internally adhere to its expected syntax and having the wrapper glue code translate requests from the internal representation to the format expected by the KubeAPI. The scheduler glue code serves as an entry point for the underlying platform to request scheduling decisions from the DECICE framework.
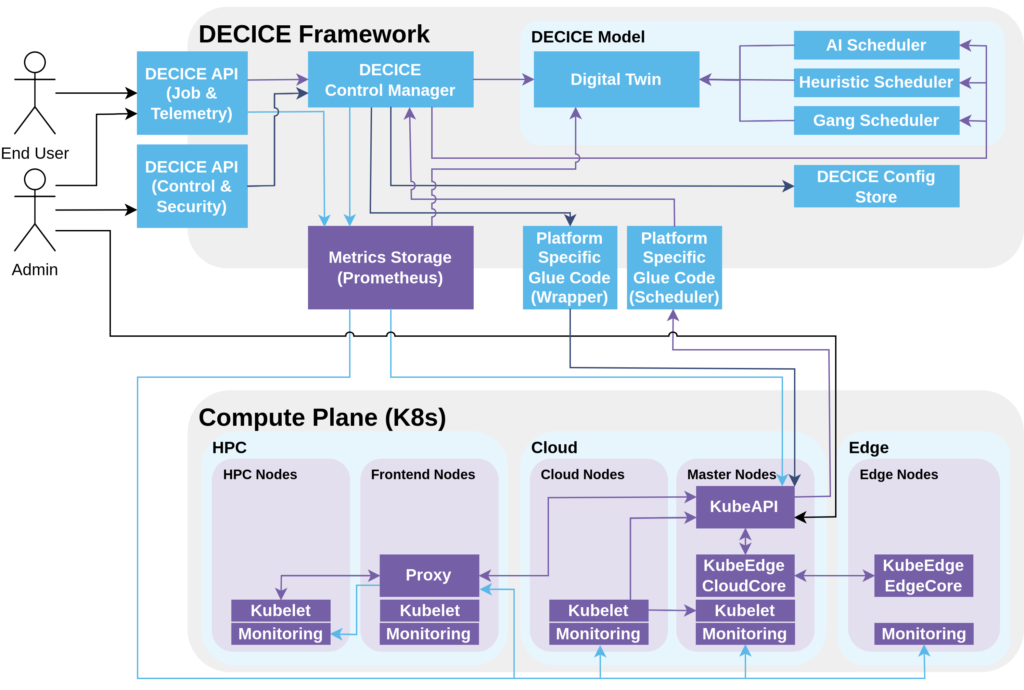
DECICE Model
The DECICE model consists of the Digital Twin and potentially one or more scheduler options. The DT contains aggregated metrics and system settings that are relevant for scheduling and job queues. It is updated by the metrics storage and the control manager and queried by the scheduler to get data for scheduling decisions. The DECICE scheduler is the key component for scheduling decisions and job placement and it queries the Digital Twin to collect data for a sophisticated scheduling decision and sends its results back to the control manager. It is capable of scheduling any number of pods/jobs/workloads. For testing purposes or different use case scenarios additional schedulers may be provided that utilize different scheduling methods (gang/batch scheduling, heuristic scheduling, AI scheduling).
Compute Plane
The compute plane is used to run user workloads across heterogeneous resources, including Cloud, High-Performance Computing (HPC), and Edge environments. The compute plane represents a resource orchestration platform that is able to run containerized jobs across a number of physical systems. In our case we consider Kubernetes as the resource orchestrator and expand it with KubeEdge to be able to manage autonomous edge devices. The compute plane utilizes Prometheus to gather metrics from devices as well as through Kubernetes/KubeEdge interfaces.
The compute plane architecture may encompass various types of nodes within the compute continuum, however, all nodes of the continuum have a monitoring stack that captures node-local data and makes it available for metrics storage via Prometheus exporters. The Kubelet component of Kubernetes is deployed on all nodes, except for the Edge Nodes, which use EdgeCore (a KubeEdge component) instead.
In the Cloud, there are Cloud Worker Nodes that are part of the cloud infrastructure. In the HPC environment, a Kubernetes stack is run on each node, and HPC Nodes are potentially equipped with accelerators such as GPUs. In many HPC systems, the nodes do not have direct internet access and rely on a proxy on the frontend nodes to access the internet in order to reduce the attack surface and potential for malicious usage. This is considered in the design as care has to be taken to enable the master nodes to use the proxy to communicate with the Kublets running on the HPC nodes. Furthermore, the proxy is also used for communicating monitoring data and for nodes on the HPC system to download data such as container images from the internet.
The new architecture serves as a foundation for a better understanding our framework and paves the way for future development processes that are coming up in the near future. Knowledge wise the DECICE project is trying to bring external as well as internal partners on the same page to get a cohesive understanding of the development of our cloud to edge platform. With this new architectural image we achieved this goal and we will keep you posted about further changes and adaptations in the future.
Author: Felix Stein
Links
https://www.uni-goettingen.de/
Keywords
GWDG, HPC, DECICE, Kubernetes, Cloud, AI, Digital Twin, Architecture, Edge Computing, Compute Continuum


