
Potential of DECICE for Federated Learning Use Cases
Federated Learning (FL) in the DECICE project involves a decentralized machine learning model shared across edge devices. In FL each device locally processes data for model training and sends updates to the central server, reducing bandwidth usage and preserving data privacy. FL offers privacy by avoiding raw data sharing and minimizes bandwidth use, though local compute power is essential for efficient training.
Federated Learning (FL) is a decentralized machine learning model in which a global prediction model is shared with multiple edge devices. Each device trains part of the model with locally available or stored data and only model updates, typically in the form of gradients, are sent to the central server. This scheme reduces the usage of network bandwidth and enhances data privacy as local training data is not transmitted.
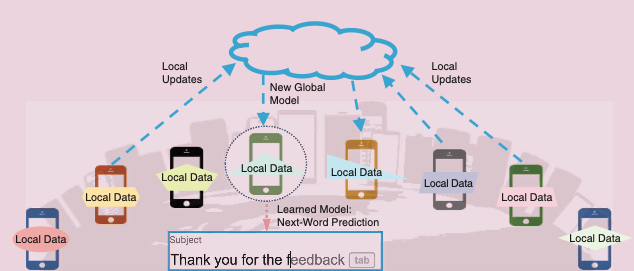
As an example, see the next-word prediction on a mobile keyboard [1], as illustrated in the following figure. User input can be used to train language models across a large number of mobile phones to predict the next word or phrase, enabling all users to benefit from auto-completing their next word based on the predictions. However, users might wish to protect their privacy and would be reluctant to share their data as well as wish to avoid wasting their limited bandwidth/battery power on their phone. According to Li et al. [1] federated learning algorithms have the potential to demonstrate the feasibility and benefit of training language models on the historical data available on client devices without exporting sensitive information to the servers.
In the setup shown in the following figure, each of the mobile phones gathers data based on user input and trains part of the model based on the local data. During each communication round a subset of mobile phones sends their locally trained model as an update to the central server. This update is much smaller than the raw data and does not easily allow for deducing the original user input from the model. The updates from the users are incorporated on the server into a new global model, which is then rolled out to a number of devices. Assuming no further updates to the training data, this process lets the network eventually converge on a global model and the training process is completed.
Scheduling in Edge Federated Learning
Edge devices are inherently heterogeneous. In each iteration of a synchronous federated learning, the participating devices need to update their computational results at the central server. Thus, training speed is dictated by the slowest device and network bandwidth. Hence, an efficient scheduler needs to allocate optimal edge resources for a given application. Currently, there are at least four major research directions to achieve this goal [2].- Participant selection: In this scheme, initially some nodes are randomly selected as participants to perform the computations using their local private data for one iteration and their training speed is analyzed. Further, the node selection is posed as a mathematical optimization problem based on the computational resources and previous training time information. The effects of different scheduling policies, e.g., random scheduling (RS), round robin (RR), and proportional fair (PF), are studied for a given problem setting [3].
- Resource optimization: Due to the heterogeneity of edge nodes, the available resources in terms of computational power and network bandwidth may vary drastically. To improve resource allocation, nodes with more compute power should be given a bigger share of compute tasks.
- Asynchronous training: The majority of edge federated learning research is focused on synchronous training, however, asynchronous training could provide an opportunity to significantly increase the capabilities of federated learning in heterogeneous environments.
- Incentive Mechanism: In environments with independent users, it might be necessary to provide some form of incentive to motivate users to collaborate in a federated learning network. Some researchers have been looking into strategies for providing compensation to users to reward them for their compute power of input data.


