

Virtual Training Environment
Today we are going to take a look at a core component of the DECICE framework – the Virtual Training Environment or Synthetic Test Environment. Training a scheduler is not an easy task and comes with a plethora of pitfalls and processing steps necessary to achieve meaningful results. For this endeavor we created a training ground that is capable of providing data to schedulers that need to be trained and fine-tuned, the DECICE Synthetic Test Environment.
The Synthetic Test Environment (STE) of the DECICE framework refers to the training and testing ground for the AI-schedulers. The purpose of an STE is to provide a controlled and repeatable environment for testing systems and software and it is a suitable training method when the costs or risks of real-world training are too high, or when STEs are the only option for providing training1,2. In our case and for the DECICE project it represents a simulation of the production environment for the actual DECICE framework together with its compute continuum. An outline of the current architecture of the STE is depicted in figure 1.
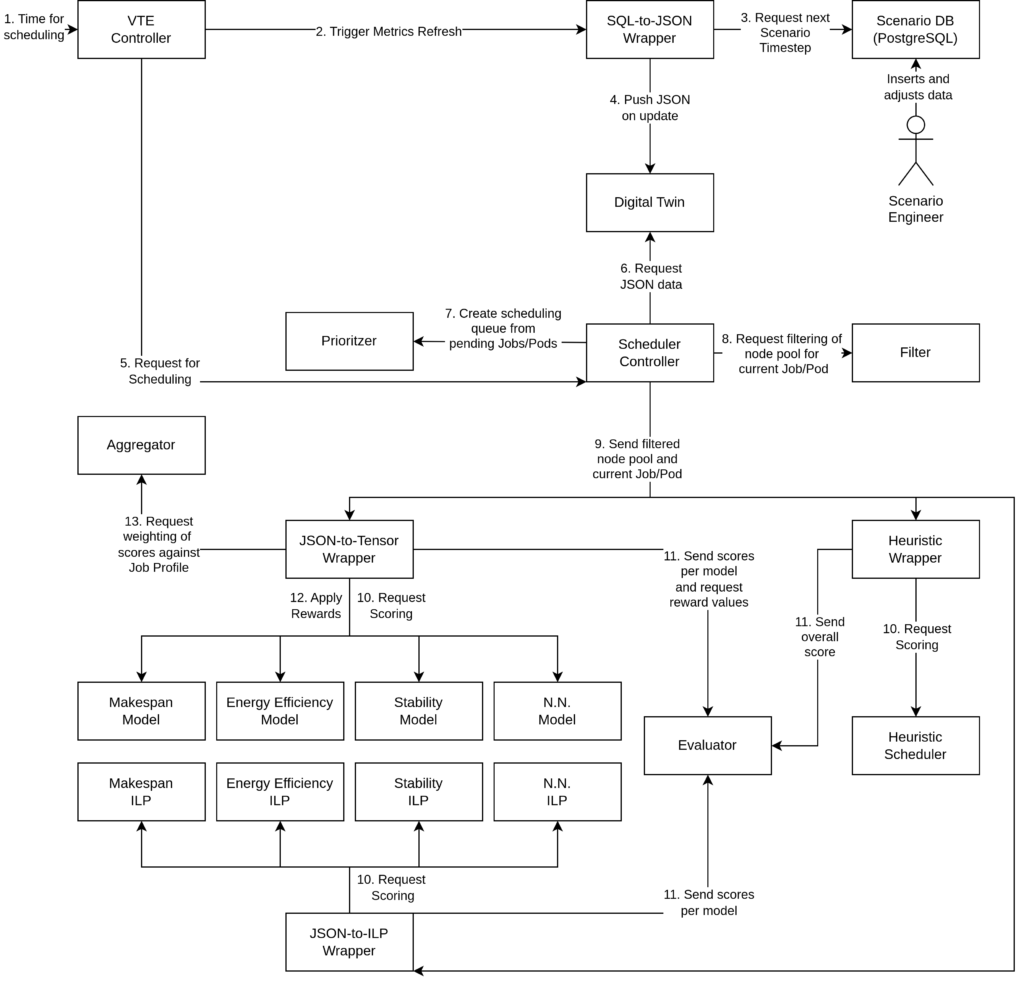
Architecture
As the purpose of the STE is to provide the environment and the control flow for training the reinforcement learning models used by the AI scheduler, the training process of the STE starts by calling the controller entity (1). It takes care of kicking off the whole training process by triggering a metrics refresh on the Digital Twin (2) by requesting training scenarios from a database (DB) (3). This ScenarioDB stores the accumulated training data as different scenarios of High-Performance Computing (HPC)/Cloud data in a PostgreSQL database. Scenarios generally refer to various hypothetical or simulated situations that are used to train the AI scheduler and to evaluate the performance, resilience, and adaptability of it. In the first iteration the DB has to be filled manually beforehand but will be replaced by an automated system in later development stages that is able to pull new data automatically from different sources (i.e. pulling metrics from a Prometheus live service). After the data has been pulled from the DB a wrapper takes care of processing the extracted data to a JSON and sends it over an HTTP API to the Digital Twin (DT) (4). In the case of the DECICE training framework it represents accumulated information of node and job metrics and holds them in memory for a fast pulling process. We already talked about the concept of a Digital Twin in one of our other newsletters. Feel free to take a look!
After the scenario data has been pushed to the DT the VTE controller entity informs the scheduler controller that new data for a training process is available (5). The scheduler controller pulls the latest data from the DT (6) and applies a prioritization to create a scheduling queue from all jobs with pending pods, ordering them based on their priority, age and whether parts of them are already running (7). A subsequent filtering step is applied to determine the pool of eligible nodes based on policies and resource requests for each pod in the current job (8). After the post-processing of the JSON data the scheduler controller sends the data of current jobs and the eligible nodes per pod to all schedulers that have been registered in the system (9). The first iteration of the DECICE training framework includes three schedulers: an AI scheduler, an Integer Linear Programming (ILP) scheduler, and a heuristic scheduler. Having three different schedulers in the training environment gives the user the flexibility to observe various scheduler models, performance differences, and to choose one of them. The heuristic scheduler, in this case, serves as a fallback option. Later iterations should also enable the possibility to use, configure, and train your own schedulers. The current number of schedulers serves only the purpose of a proof of concept, and there could be more or fewer schedulers in the future, including your own scheduler. The respective wrapper converts the JSON into a format that can be used by each individual scheduler. In the case of the JSON-to-Tensor Wrapper, the JSON data is converted to tensors that can be processed by machine learning (ML) models, which are then send to multiple models that each score the nodes eligible for a given pod. In the case of the JSON-to-ILP Wrapper it is send to multiple ILP models that compute the optimal scheduling decision based on their respective optimization target. In both cases the N.N. Model or N.N. ILP symbolizes further models and ILPs with additional optimization targets (10).
After a run through all three wrappers send their scores to the evaluator component which compares the scores from the AI schedulers to the scores from the ILP scheduler while using the heuristic scheduler as a fall back (11) and sends them back for applying reward scores to the individual models (12). The Aggregator weighs the scores and sends the final scheduling decisions back to the scheduler controller (13).
We hope this short introduction to our DECICE training framework gives a good overview of what you can expect in the upcoming future. Stay tuned for regular development updates in 2024!
Author: Felix Stein
Reference
1 – F. D. Rose et al. “Training in virtual environments: transfer to real world tasks and equivalence to real task training”. In: Ergonomics 43.4 (Apr. 2000), pp. 494–511. doi: 10.1080/001401300184378.
url: https://doi.org/10.1080/001401300184378
2 – Daniela M. Romano and Paul Brna. “Presence and Reflection in Training: Support for Learning to Improve Quality Decision-Making Skills under Time Limitations”. In: CyberPsychology & Behavior 4.2 (Apr. 2001), pp. 265–277. doi: 10.1089/109493101300117947. url: https://doi.org/10.1089/109493101300117947 .
Links
See also the News Article about “Digital Twin”.
Keywords
DECICE, Cloud, Machine Learning, ML, Virtual Training Environment, VTE, Synthetic Test Environment, STE


